- Published on
GFS - Post-Paper Analysis, Reflections, and Questions
- Authors

- Name
- Bryce Yu
- @earayu
概述
Google File System 是由Google在2003年的论文中提出的一个分布式文件系统。GFS面向的存储场景以大文件为主,主要负载为大容量连续读、小容量随机读以及追加式的连续写。设计的侧重点在于:如何在获取分布式文件系统容量、性能、可扩展性收益的同时,权衡好容错,可靠性的成本问题。所以,通篇论文给我最大的感受是这些收益和成本之间微妙且平衡的取舍。在此之中,也能感受到计算机科学无与伦比的魅力。怪不得计算机科学也总是被称之为“The art of the trade off”。
本文的内容主要是基于GFS论文中提出的一些关键设计,进行一些个人分析与思考。同时也还有一些论文中缺乏的细节,以及个人在查阅资料、求证未果的情况下仍然存在的一些疑问。限于篇幅不会对GFS的设计细节和实现作太多的描述。
中心化单点Master
GFS中主要存在3个实体:
- Client:以library的形式集成于应用中,用于驱动GFS中的各种文件操作。
- Master:管理几乎所有的元数据,包括文件和chunk的映射、chunk和chunkserver的映射。
- Chunkserver:文件以chunk的形式存储于chunkserver中,每个chunk会有多个备份(replica)。
本节主要讨论Master。
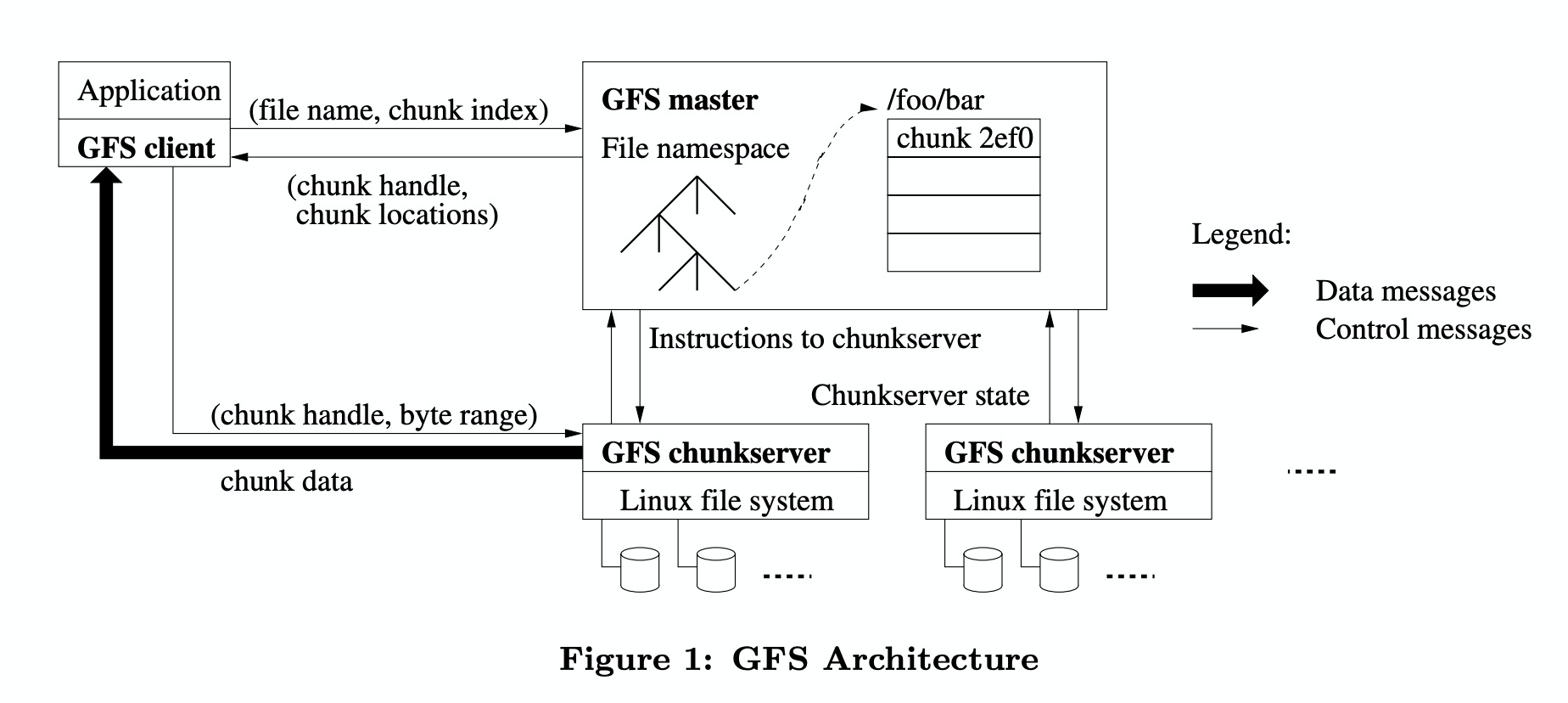
单节点设计
由于所有的读写操作都会先经过Master节点(不算client缓存),最让我意外的,莫过于Master节点是一个单点。它把所有的Metadata(元数据)都存储在单一进程的内存中。当然部分Metadata也会持久化存储到本地磁盘,操作日志也会同步到远程Master节点。单点意味着一旦Master节点故障,整个GFS都会变得不可用。但是GFS把Master节点设计成能够秒级恢复,同时client会缓存部分Metadata。很有可能Master节点故障之后快速恢复了,以至于很多client都没有意识到Master发生过故障。
中心化的单节点会使分布式系统容易出现可用性问题,GFS的解决方案就是快速恢复+客户端缓存。
当然,付出了可用性的成本后,使用中心化单节点的收益也是明显的:它极大地简化了系统设计,让我们无需关心Master节点之间的一致性问题。
所以,GFS这块的设计取舍就是:用A换取C;用快速恢复+客户端缓存提高A(虽然又因此降低了一些C)。
元数据一致性问题
client的任何对文件的操作,都会在Master节点处形成Operation Log(操作日志)。Master节点会分别写入本地磁盘、多个远程Master节点、本地内存。全部写入成功后,会返回“成功”给client。但问题在于,从论文来看,元数据在Master上的更新操作不是原子性的。
假如写入本地磁盘后Master节点立刻故障,如果此时重启的是原先的Master节点,可以根据本地磁盘的Operation Log把刚刚的更新操作恢复到内存里,但远程Master没有得到更新,client也没有收到“成功”的消息;如果此时重启的是远程的Master节点,则它的本地磁盘没有刚刚的Operation Log。不管怎样,client都没有收到“成功”的消息。论文没有详述,**但我觉得GFS采取的策略应该是:Master节点支持了元数据操作的幂等。**这样的话,client只要没收到“成功”的返回,就可以放心地不断重试该操作。
论文还提到,Master可以将一些元数据操作批量放内存里,然后再刷入磁盘。对于这块我没有找到更多的信息,元数据操作在远程Master上的顺序可能是不同的,这又可能会导致一致性问题。PS:对于数据写操作,GFS让primary chunkserver决定写入的顺序,并最终同步给secondary。批量元数据操作在多个Master节点间的同步,也许也可以借鉴一下这个思路。
过期数据问题
因为client会缓存元数据,所以client有可能会读到一个“过期”的chunkserver,从而读取到“过期”的数据。这是怎么发生的?chunkserver故障后,它错过了一个对chunk A的写操作,然后chunkserver重启了。此时client仍然认为该chunkserver是有效的,所以从它那儿读取数据,最终导致了读到过期数据的问题。
同理:Shadow Master因为存在与Master的延迟,也会导致读到过期数据的问题。
这块,更多的是性能和一致性之间的取舍
chunk size的取舍
一个文件由一个或多个chunk组成。Master为了性能,将元数据都放置到内存中,而元数据的量级与文件的容量呈正相关。所以,可以说Master的内存容量决定了GFS的扩展性。
chunk的粒度(或者说size)对很多方面都有影响:
较大的chunk size可以减少metadata的数据量,从而带来可更好的metadata查询性能;让GFS能拥有更好的扩展性;
较大的chunk size可以减少client和master的通讯次数,减少Master节点的QPS;
但是,较大的chunk size也会使得某一块chunk更容易成为热点。如果有很多并发随机写的话,会出现严重争用问题(后面会讨论到)。如果有很多record append writes(追加写)的话,也有可能造成空间浪费或者重复数据增多的问题。GFS选取的chunk size是64MB(还挺大的),能够work around的原因在于:在GFS面向的业务场景下,大多工作负载都是顺序读,追加写也远多于随机写。
这边权衡的点在于:性能、扩展性 VS 空间利用率,数据一致性
chunk的大小参数,乍看不起眼,实际上取决于Google的业务场景,又影响了Master的设计。读写操作的很多设计也跟chunk size有关。太有趣了!
一致性模型
**凡是存在分布式多副本写入的系统,必然需要面对一致性问题。**GFS放宽了一致性约束,换取了性能、简单性......
GFS的一致性问题可分为元数据的一致性问题和文件的一致性问题。对于元数据来说,GFS使用了排他锁,又由于Master是单节点,所以这一块比较简单,不再赘述。接下来讨论的主要是文件的一致性问题。
针对可能出现的数据状态,GFS做出了几个精彩的定义:
- consistent:客户端无论读取哪个replica(副本),得到的数据都是一样的;
- defined:客户端能看到上次修改的完整内容,且这部分内容是consistent的;
所有并发的随机/追加写,最终都会使某个chunk落入如下表所示的某个状态中。对于client来说,它只关心defined的数据,它需要忽略所有inconsistent和undefined的数据。
PS:从表中可以看出,并发写(同一块offset)一定会导致undefined。印证了GFS的主要用户场景不在随机写。

并发随机写
从上表中可以看到,“随机并发写”会导致“consistent but undefined”。
“随机并发写”最大的问题在于,它们写入的offset(位置)可能是重叠的。设想这样一种场景:
- client A写入一个值 foo;同时client B在同一个位置写入一个值bar;
- client负责写入所有的replica,但是顺序由primary决定并同步给其他所有secondary;
- 由第2点可以保证所有replica的数据都是一致的(不考虑失败情况),但是最终数据到底是foo还是bar?这一点,对于client来说是不确定的。所以最终状态对于client来说是undefined。
并发追加写
“并发追加写”不关心写入的具体offset,所以它不会有“并发随机写”的问题。但它有自己的问题:为了保证每次写入的offset一致,必然会出现failure时部分写入成功,部分写入失败,最终导致数据不一致。
具体会导致数据不一致的情景如下:
- client A追加写入foo成功;
- client A追加写入bar部分成功,其中primary和secondary1成功,secondary2失败;
- client A追加写入baz成功;
- client A重试追加写入bar成功;
最终数据在3个replica的结果如下:
primary: foo;bar;baz;bar;
secondary1: foo;bar;baz;bar;
secondary2: foo; ;baz;bar;
GFS保证了每次record append的offset是一致的(由primary决定),并且全部replica成功才算成功写入,但仅此而已了。如果出现了失败的情况,它不会去负责把那部分数据纠正。因为一旦需要考虑修正(分布式强一致性),就会变得很复杂,也会很大地影响性能,这是分布式共识算法需要解决的问题。
这一部分不一致的数据需要application来“兼容”,方式是幂等和计算校验和。
总结
通篇论文让我最大的感受是“权衡”,但这些“权衡”建立在清晰的设计目标上,最终的源头是对Google业务的深刻理解与抽象。当需要做出权衡时:GFS选择高数据吞吐量而不是低延时,选择高性能而不是强一致性。但它对于战略舍弃的东西,也并不是全部放任不管,而是会额外引入一些其他机制来再提高一些保证,比如上文提到的单点Master和client缓存。这让我想起了kafka对于消息投递和接受的策略:默认不是at least once,也不是at most once,而是极有可能丢失,又有可能重复。庞大系统的设计,总是建立在对业务的深刻理解与抽象上的,GFS很好地实践了这一点。
论文中还有很多有趣的设计,比如lease、snapshot、garbage collection等等,不一一而足。对于GFS后续的升级,以及其他的分布式文件系统,可能遵循的又是另一套设计思路......
疑问
GFS如何处理分布式下时钟问题?
lease机制跟时间强相关,但分布式下时间可能存在一系列问题。比如一个chunkserver如何判断它自己的lease过期了呢?它的lease的开始时间可以来自于master,但这样的话也意味着不能用它自己的时钟来判断lease结束时间,因为它的时钟和master总是有差距的。
我的想法是:也许GFS不关心这个问题。因为首先时钟问题的尺度一般较小(毫秒级?),其次还有更多问题会导致不一致的发生,而GFS本身就把这些不一致作为了trade off使用掉了。
Master故障后如何确定新Master?
原Master、远程Master(多个)、Shadow Master(多个)都有可能成为新Master,但如何选择呢?也许需要有个人来手工操作,但这也意味着故障时间会极大地增加。
lease为什么默认是60s?会导致上层应用哪些问题?
lease的引入可以解决脑裂问题。这也是一个trade off,因为lease很简单很容易实现,但也降低了可用性。如果出现了故障,是否意味着可能该chunk 60s内都有可能不可用?